NavaiSTT-2v Medium: A Fully Open-Source Uzbek Speech-to-Text Model
About NavaiSTT v2
This is the second version of the NavaiSTT model, representing a classic Whisper medium model fine-tuned for the Uzbek language. This release prioritizes transparency, reproducibility, and community access.
The key difference from v1 is that v2 is fully open-sourced. Due to conflicts with data partners, the v1 model and its proprietary 500-hour dataset were removed. For v2, I have curated a new set of publicly available and permissively licensed datasets. Critically, both the final dataset and the training scripts will be open-sourced, making the entire fine-tuning process fully repeatable by anyone in the community.
Special attention was again given to Tashkent dialect audio, resulting in strong performance for this common dialect. Future work will focus on incorporating more regional dialects to improve coverage across Uzbekistan.
Model Details
Base Model: Whisper Medium
Parameters: 769M
Word Error Rate (WER): ~17%
Character Error Rate (CER): ~5.5%
Training Data & Methodology
This model was fine-tuned on approximately 475 hours of diverse Uzbek audio data. The dataset was composed of 50% human-transcribed and 50% pseudo-transcribed material (using Gemini 2.5 Pro).
The training corpus included:
- Common Voice 17 dataset (filtered)
- USC (filtered)
- Google fleurs (filtered)
- Podcasts Tashkent Dialect Youtube Uzbek Speech Dataset
- News Youtube Uzbek Speech Dataset
- IT Youtube Uzbek Speech Dataset
A custom script was used to filter the datasets based on Word Error Rate (WER) and similarity checks to ensure data quality. This filtering script will also be open-sourced as part of our commitment to a fully repeatable process.
Open-Sourced Datasets for Full Reproducibility
All datasets used to train NavaiSTT-2v have been open-sourced to enable complete reproducibility of the training process. The following datasets are available on Hugging Face:
Training and Filtering Code
The complete training pipeline, including data filtering and model fine-tuning scripts, is available for anyone who wants to reproduce or improve upon NavaiSTT-2v:
🚀 View Training Code on GitHub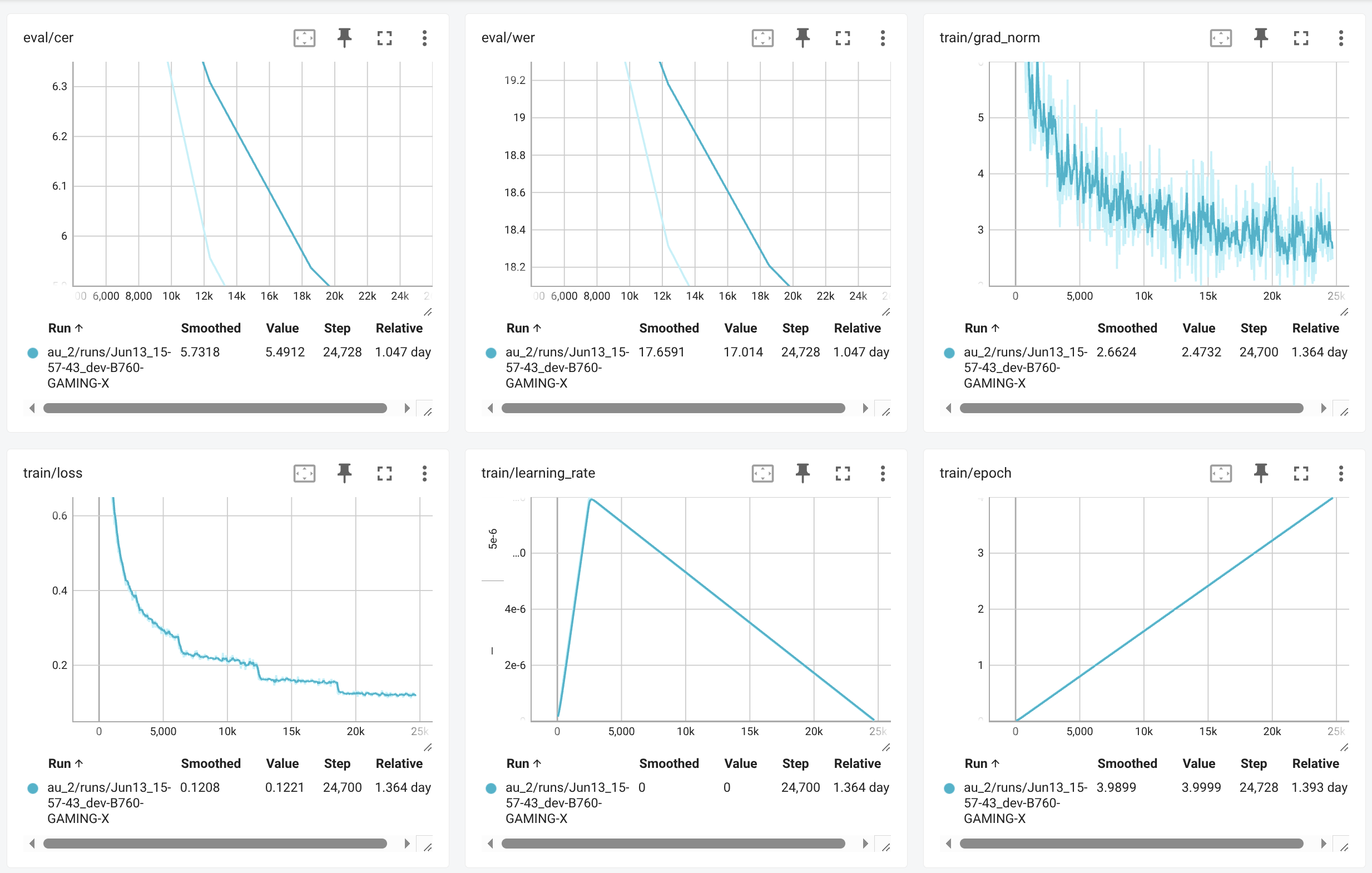
Performance Comparison
Listen to the sample below and compare NavaiSTT-2v Medium transcription accuracy with other leading services and our previous model:
| Audio | NavaiSTT-2v Medium | NavaiSTT-1v Medium | Muxlisa AI service: 16.06.2025 | AIsha STT service: 16.06.2025 | Uzbekvoice STT service: 16.06.2025 |
|---|---|---|---|---|---|
|
Everyday IT speech. Nuruddin Test
|
kecha orqinjon bitta disk olti yuz gb qilganman o'zimda. disk siz ichiga kirsangiz, bitta olti yuz gb lik menimcha disk turibdi eng katta. o'shani anavi qilsangiz, agar format qilish kerak bo'lsa, endi boshqa iloji yo'q bo'lsa, format qilib ustidan yozsangiz ham bo'ladi, chunki u backup ku, hozir hech narsa qilmadik hali u data bilan. | kecha yorqinjon bitta diskka olti yuz gb qilganman o'zimda. disk si ichiga kirsangiz, bitta olti yuz gblik menimcha disk turibdi eng katta. o'shani anaqa qilsangiz. agar format qilish kerak bo'lsa, endi boshqa iloji yo'q bo'lsa, format qilib, ustidan yoshsangiz ham bo'ladi. chunki u back up ku, hozir hech narsa qilmadik hali u data bilan. | Kecha yorqinjon bitta disk olti yuzga bayt qiyami, o‘zimda disksi chegirsiz bitta olti yuzga baytli bamchi disk turibdi eng qotdi o‘shani, anuqsiz. Agar format qilish kerak bo‘lsa, endi boshqa iloji bo‘lsa, format qilib, ustun-ayoshidan bo‘ladi, chunki u bekafga ozishni qimmatli halol, deydi bilan. | kecha yorqinjon bitta disk olti yuz gbayt qiyaman o'zimda disk stichga kirsangiz bitta olti yuz gbaytlik menimcha disk turibdi eng katta o'shani anavi qilsangiz agar format qilish kerak bo'lsa endi boshqa iloji yo'q bo'lsa flsa format qilib ustidan yozsangiz ham bo'ladi chunki u baribir bekabku hozir hech narsa qilmadiy hali oldaetamaan | kejak orqanjon bitta disk olti yuzga vayt qilyaman o'zida diskiichga kirsangiz bitta olti yuzga vaytli monimcha disk turibdi eng katta oshani anovi qilsangiz agar format qilish kerak bo'lsa endi boshqa iloji yo'q bo'lsa format qilib ustidan yozsangiz ham bo'ladi chunki u bbbakabku hozir hech narsa qilmadik hali unda aytaman |
|
Tashkent dialect in noisy environment.
|
lapshalarni olib kirayotganda rastamoshka to'lamagansan. qanaqa rastamoshka? firmadan olaman ku men buni. gapni ko'paytirmaman. ol. | lapshalarni olib kirayotganda rastamoshka to'lamagansan. qanaqa rastamoshka? firmadan olaman ku men uni. gapni ko'paytirmayman, ol. | Ularchalarni opkirib o‘tganda rasta-moshka to‘lamagansan.Anaqa rasta-moshka filmidan olamayman. Nega so‘p aytirmaman, o‘t! | labchalarni olib kirayotganda rastamoshka to'lamangansan qanaqa rastamoshka firmada olamankoat | labshalani olib kirayotganda rastamoshka to'lamangasa qanaqa rastamoshka firmada olamankukazni ko'paytiribman men o |
|
Old classic Uzbek language.
Audiobook: O'tgan kunlar |
endi boyog'i qarag'anda biroz yengillangan sumon, jon olg'uvchi qora ko'zlari harakatlana boshlag'an, bo'g'riqqan qizil yuzlari ochilinqiragan edilar. | endi boyag'i qarag'anda biroz yengillangansumon jon olg'uchi qora ko'zlari harakatlana boshlag'an, bo'g'riqqan qizil yuzlari ochilinqirag'an edilar. | Endi boyag‘i qarag‘anda biroz yengillagan sumon, jon olg‘uchi qorako‘zlari harakatlana boshlag‘an bo‘g‘riqqan qizil yuzlari ochilinqirag‘an edilar. | endi boyog'i qarag'anda biroz yengillangan simon jon olg'uchi qora ko'zlari harakatlana boshlag'an bo'g'ruqqan qizil kuzlari ochilim qirag'an etilar | endi boyog'i qaraganda biroz yengillangan sumon jon olg'uvchi qora ko'zlari harakatlana boshlag'an bog'ruqqan qizil yuzlari ochilin qirag'an edilar |
|
Random women voice with numbers. Clean
|
endi kuniga yigirma ikki ming uch yuz so'mdan ko'p sarflagan yurtdoshlarimiz rasman kambag'al hisoblanmaydi. o'zbekistonda kambag'allik chegarasi yangilanib, bir kishining bir oylik minimal iste'mol xarajatlari olti yuz oltmish to'qqiz ming so'm etib belgilandi. ushbu raqam ikki ming yigirma to'rtinchi yil may oyidan beri olti yuz qirq sakkiz ming so'mni tashkil qilib kelayotgandi. statistika agentligiga ko'ra, minimal iste'mol xarajatlari qiymatini hisoblash tartibiga asosan, ilgusi yigirma uchun minimal iste'mol xarajatlari oziq ovqat, nooziq ovqat mahsulotlari va xizmatlar narxlari darajasidan kelib chiqib, indeksatsiya qilib boriladi. | endi kuniga yigirma ikki ming uch yuz so'mdan ko'p sarflagan yurtdoshlarimiz rasman kambag'al hisoblanmaydi. o'zbekistonda kambag'allik chegarasi yangilanib, bir kishining bir oylik minimal iste'mol xarajatlari olti yuz oltmish to'qqiz ming so'm etib belgilandi. ushbu raqam ikki ming yigirma to'rt yil may oyidan beri olti yuz qirq sakkiz ming so'mni tashkil qilib kelayotgandi. statistika agentligiga ko'ra, minimal iste'mol xarajatlari qiymatini hisoblash tartibiga asosan shilgusi yigit uchun minimal iste'mol xarajatlari, oziq ovqat, noziq ovqat mahsulotlari va xizmatlari narxlari darajasidan kelib chiqib, indeksatsiya qilib boriladi. | Endi kuniga yigirma ikki ming uch yuz so‘mdan ko‘p sarflagan yurtdoshlarimiz rasman kambag‘al hisoblanmaydi. O‘zbekistonda kambag‘allik chegarasi yangilanib, bir kishining bir oylik minimal iste’mol xarajatlari olti yuz oltmish to‘qqiz ming so‘m etib belgilandi. Ushbu raqam ikki ming yigirma to‘rtinchi yil may oyidan beri olti yuz qirq sakkiz ming so‘mni tashkil qilib kelayotgandi Statistika agentligiga ko‘ra, minimal iste’mol xarajatlari qiymatini hisoblash tartibiga asosan, kelgusi yil uchun minimal iste’mol Xarajatlari oziq-ovqat, nooziq-ovqat mahsulotlari va xizmatlar narxlari darajasidan kelib chiqib, indeksatsiya qilib boriladi. | endi kuniga yigirma ikki ming uch yuz so'mdan ko'p sarflagan yurtdoshlarimiz rasman kambag'al hisoblanmaydi o'zbekistonda kambag'allik chegarasi yangilanib bir kishining bir oylik minimal iste'mol xarajatlariari olti yuz oltmish to'qqiz ming so'm etib belgilanadi ushbu raqam ikki ming yigirma to'rtinchi yil may oyidan beri olti yuz qirq sakkiz ming so'mni tashkil qilib kelinayotganda statistika agentligiga ko'ra minimal iste'mol xartlari qiymatini hisoblash tartibiga asosan kelgusi yilchi minimal iste'mol xarajatlari oziqovqat nooziqovqat mahsulotlari va xizmatlar narxlari darajasidan kelib chiqib indeksatsiya qilib boriladi | endi kuniga yigirma ikki ming uch yuz so'mdan ko'p sarflagan yurtdoshlarimiz rasman kambag'al hisoblanmaydi o'zbekistonda kambag'allik chegarasi yangilanib bir kishining bir oylik minimal iste'mol xarajatlari olti yuz oltmish to'qqiz ming so'm etib belgilandi ushbu raqam ikki mi yigirma to'rtinchi yilmay oyidan beri olti yuz qirq sakkiz ming so'mni tashkil qilib kelayotgandi statistika agentligiga ko'ra minimal iste'mol xarajatlari qiymatini hisoblash tartibiga asosan kelgusi yil uchun minimal iste'mol xarajatlari oziqovqat nooziq ovqat mahsulotlari va xizmatlar darajasidan kelib chiqib indeksatsiya qilib boriladi |
|
Old audio with bad quality.
Shum Bola |
yarim kechada sheriklaring bilan kelgansan, boy otamni sheriklaring bilan tunagansan, pulni qayerga yashirganini sen bilasan, sen, sen, sen! ha, to'ppa! boy otamni ham to'ydim, ho'kirni ham oldirdim, eshakni ham to'ydim, imomni ham oldirdim! | yarim kechada sheriklaring bilan kelgansan, boy otam sheriklaring bilan tunagansan, pulni qayerga yashirganini sen bilasan. sen, sen, sen! ha, bo'pti! boy otamni ham so'ydim, xokirni ham o'ldirdim, eshakni ham so'ydim, imomni ham o'ldirdim! | Yarim kechada sheriklaring bilan kelgansan, boy otam sheriklaring bilan tunagansan, pulni qayerga yashirganini sen bilasan, sen, sen, sen... | yarim kechada sheriklaring bilan kelgansan voy otamni sheriklaring bilan tunagansan pulni qayerga yashirganni sen bilasan sen sen sen bod | yarim kechada sheriklaring bilan kelgansan boy otamni sheriklaring bilan tunagansan pulni qayerga yashirgandi sen bilasan sansansan aaodam oiao eaodaa |
|
Long uzbek language poem
|
ikki xushomadgo'y uchrashdi bir kun. ochig'i tajriba almashmoq uchun. shundoq boshlab qoldi gapni, havaskor. mening qalbim to'la, g'urur, iftixor. oxiri meniki bo'ldi xo'jayin. ishlarim yurishib ketmog'i tayin. u kun o'zi ko'zlarini yaladim ancha tovonidan tortib tizzasigacha. gal keldi ikkinchi xushomadgo'yga. gapin boshladi u qolgancha o'yga. hozirgi kasbdoshlar o'zgargan butkul, kamtarlikni bilmas, maqtanar nuqul. mana biz dongormiz, taniydi har kim. lekin o'tiribmiz gerdaymasdan jim hey sen ishonmaysan ey sodda ukam yalaganmiz undan yuqorisini ham | ikki xushomadgo'y uchrashdi bir kun, ochig'i, tajriba almashmoq uchun. shundoq boshlab qoldi gapni havaskor, mening qalbim to'la g'urur, iftixor. oxiri meniki bo'ldi xo'jayin, ishlarim yurishib ketmog'i tayin. u kun o'zgardi, ko'zlarini yaladim ancha, tovonidan tortib tizzasigacha. gal keldi ikkinchi xushomad go'yga, gapin boshladi u qolgancha o'yga. hozirgi kasbdoshlar o'zgargan butkul, kamtarlikni bilmas, maqtanar nuqul. mana biz dongdormiz, taniydi har kim, lekin o'tiribmiz gerdaymasdan, jim! aytsam ishonmaysan, ey, sodda ukam, yalaganmiz undan yuqorisini ham. | Ikki xushomadgo‘y uchrashdi bir kun, ochig‘i, tajriba almashmoq uchun. Shundoq boshlab qoldi gapni havaskor, mening qalbim to‘la g‘urur, iftixor. Oxiri meniki bo‘ldi xo‘jayin, ishlarim yurishib ketmog‘i tayin. U kun o‘zlarini yaladim ancha, tovonidan tortib tizzasiga chek.Gal keldi ikkinchi xushomadgo‘yga, gapin boshladi u solgancha o‘yga. Hozirgi kasbdoshlar o‘zgargan butkul, kamtarlikni bilmas, maqtanar nuqul. Mana biz dongdormiz, taniydi har kim, lekin o‘tiribmiz, gerdaymasdan jim. Ey, sen ishonmaysan, ey, sodda ukam, yalaganmiz undan yuqorisini..Aham! | ikki xushamadjoy uchrashdi bir kun ochig'i tajriba almashboq uchun shundoy boshlab qoldi gapni havaskor mening qalbim to'laururiftixor oxiri meniki bo'ldi xo'jayin ishlarim yurishib ketmagu tayin u kun o'zlarini yanadim ancha tovonidan tortib kizlasigacha yali keldi ikkinchi xi xushamad bo'yga gapin boshladi u solgancha o'yga hozirgi kasbdoshlar o'zgargan bupul kamtarllikni bilma maqtanar nuqul mana biz dongdormiz taniydi har kim lekin o'tiribmi gerdaymasdan jim aytdam ishonmaysan e sodda ukam yalaganmiz undan yuqorisin ham | ikki xushamad go'y uchrashdi bir kun ochig'i tajriba almashmoq uchun shundoq boshlab qoldi gapni havasbor menig qalbim to'la g'urur istiqor oxiri meniki bo'ldi xo'jayin ishlarim yurishib ketmoqi qayin u kun o'zlarini yanadim ancha tovonidan tortib kezzasigacha tezzasiga yal keldi ikkinchi xushomod bo'yga gapini boshladi u solgancha o'yga hozirgi kasb doshlar o'zgargan bukul kamtarlikni bilmas maqtanar nuqul mana biz dongdormiz taniydi har kim lekin o'tiribmiz yerdaymasdan jim aysam shonmaysan ey sodda ukam yalaganmiz undan yuqori sin ham |
Thoughts on Open Source vs. Commercial
Let's be honest - most startups don't need open source AI models unless they are facing specific legal restrictions. Gemini 1.5, 2, 2.5 Pro delivers remarkably human-like performance, especially for transcription where it captures nuanced speech with accuracy that rivals human ears. When you hear someone speaking, this model understands exactly as you would.
However, when handling sensitive personal data that cannot be shared with foreign third parties, such as private audio recordings containing confidential information, regionally-hosted services or self-hosted open source alternatives (like NavaiSTT) provide necessary compliance and data sovereignty.
Implementation Example
Integrating NavaiSTT v2 into your application is straightforward using the Transformers library. Here's a Python code example:
import torch
import torchaudio
from transformers import WhisperProcessor, WhisperForConditionalGeneration
def transcribe_audio(audio_path, model_path):
"""Simple function to transcribe audio with a fine-tuned Whisper model"""
# Load model and processor
processor = WhisperProcessor.from_pretrained(model_path)
model = WhisperForConditionalGeneration.from_pretrained(model_path)
# Move to GPU if available
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# Load and preprocess audio
waveform, sample_rate = torchaudio.load(audio_path)
if sample_rate != 16000:
waveform = torchaudio.functional.resample(waveform, sample_rate, 16000)
# Convert to mono if needed
if waveform.shape[0] > 1:
waveform = waveform.mean(dim=0, keepdim=True)
# Process audio
input_features = processor(
waveform.squeeze().numpy(),
sampling_rate=16000,
return_tensors="pt"
).input_features.to(device)
# Generate transcription
with torch.no_grad():
predicted_ids = model.generate(input_features)
# Decode
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
return transcription
# Example usage
if __name__ == "__main__":
MODEL_PATH = "islomov/navaistt_v2_medium"
# Make sure to create a dummy audio file named "some_audio.wav" for this to run
audio_file = "some_audio.wav"
text = transcribe_audio(audio_file, MODEL_PATH)
print(f"Transcription: {text}")