NavaiSTT-1v Medium: Uzbek language Fine-tuned Whisper medium Speech-to-Text model
Important Update on NavaiSTT-1v
The NavaiSTT-1v Medium model has been removed due to unforeseen conflicts with some of the data providers. I sincerely apologize for any inconvenience this may have caused. My goal is to always respect data ownership and licensing agreements.
From v1 to v2: A Commitment to Open Source
As compensation for the removal of v1, and to further my commitment to transparent and accessible AI, I have released NavaiSTT v2. This new version is fully open-source, and most importantly, it was trained on a new, fully open-sourced dataset that I have also made public. This ensures complete transparency and repeatability for everyone in the community.
The rest of this page is preserved as an archive of the original v1 model for historical reference.
NavaiSTT-1v Medium (Archived)
Classic Whisper medium model fine-tuned for Uzbek language. The dataset included ~700 hours of diverse audio: publicly available podcasts, Tashkent dialect podcasts, audiobooks, and Common Voice 17. Data quality was mixed with 60% human transcribed and 40% pseudo-transcribed using Gemini 2.5 Pro.
Special attention was given to Tashkent dialect audio materials, resulting in strong performance on this dialect. Future versions will include other regional dialects to improve overall coverage.
Original Model: Whisper Medium
Parameters: 769 M
Wer: ~13%
Cer: ~3.5%
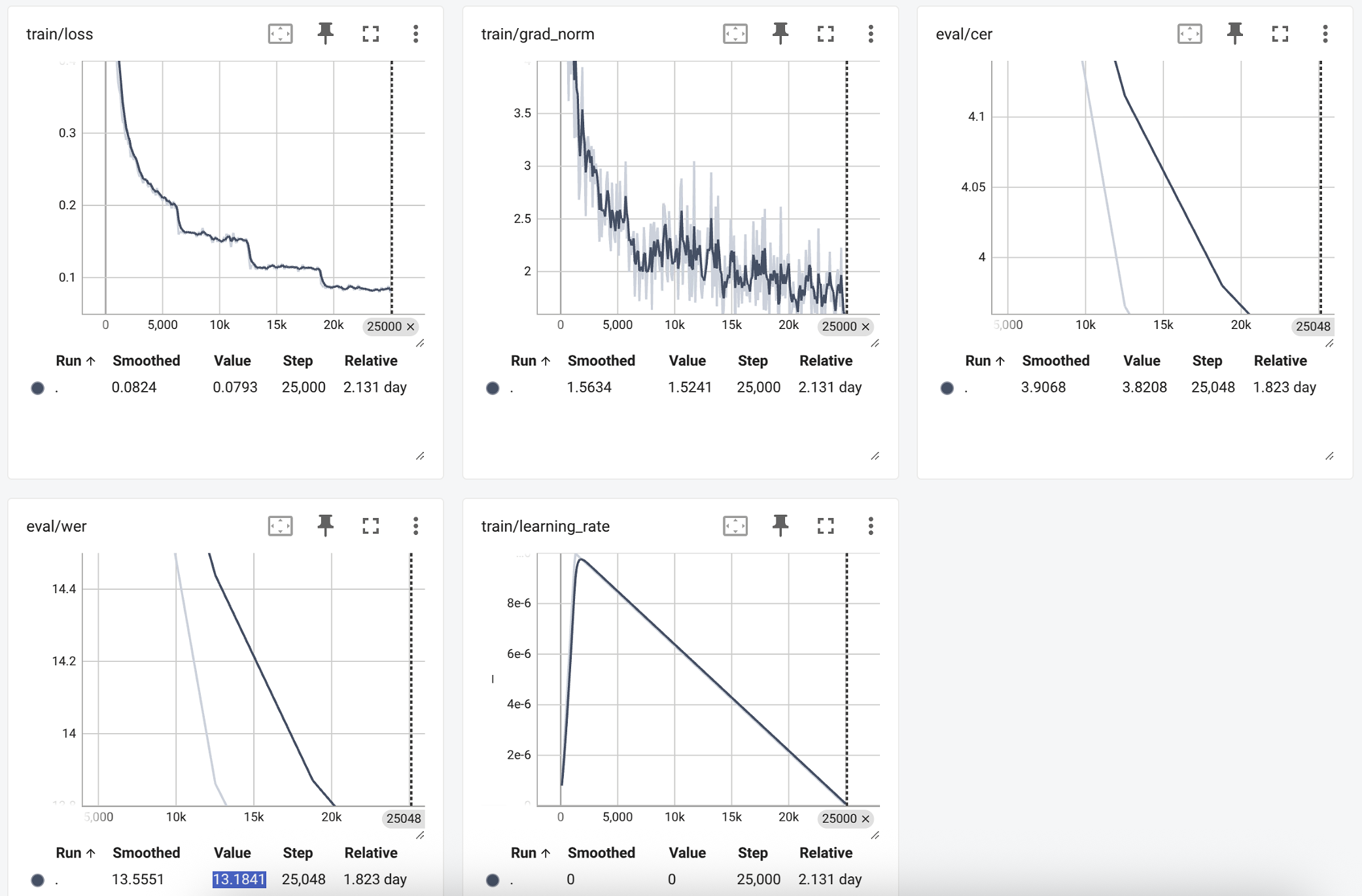
This is only the first version of this model. Based on how helpful it proves for users, I will begin work on v2. I already have a clear vision for how to improve the model further.
Performance Comparison
Listen to the sample below and compare NavaiSTT-1v Medium transcription accuracy with other leading services:
| Audio | NavaiSTT-1v Medium | AIsha STT service: 02.05.2025 | Uzbekvoice STT service: 02.05.2025 |
|---|---|---|---|
|
Everyday IT speech. Nuruddin Test
|
kecha yorqinjon bitta diskka olti yuz gb qilganman o'zimda. disk si ichiga kirsangiz, bitta olti yuz gblik menimcha disk turibdi eng katta. o'shani anavi qilsangiz. agar format qilish kerak bo'lsa, endi boshqa iloji yo'q bo'lsa, format qilib, ustidan yoshsangiz ham bo'ladi. chunki u backup ku, hozir hech narsa qilmadik hali u data bilan. | kecha yorqimjon bitta disk olti yuz gbat qiyaman o'zimda disk stichga kirsangiz bitta olti yuz gbatli menimcha disk turibdi eng katta o'shaniavi qilsangiz agar format qilish kerak bo'lsa endi boshqa iloji yo'q bo'lsa format qilib ustidan yozsangiz ham bo'ladi chunki u baribir bekabku hozir shu narsa qilmadiy hali udatamaa | kejak orqanjon bitta disk olti yuzga vayt qilyaman o'zida diskiichga kirsangiz bitta olti yuzga vaytli monimcha disk turibdi eng katta oshani anovi qilsangiz agar format qilish kerak bo'lsa endi boshqa iloji yo'q bo'lsa format qilib ustidan yozsangiz ham bo'ladi chunki u bbbakabku hozir hech narsa qilmadik hali unda aytaman |
|
Tashkent dialect in noisy environment.
|
lapshalarni olib kirayotganda rastamoshka to'lamagansan. qanaqa rastamoshka? firmadan olaman ku men uni. gapni ko'paytirmayman, ol. | labchalarni olib kirayotganda rastamoshka to'lamangansan qanaqa rastamoshka firmada olamankoat | labshalani olib kirayotganda rastamoshka to'lamangasa qanaqa rastamoshka firmada olamankukazni ko'paytiribman men o |
|
Old classic Uzbek language.
Audiobook: O'tgan kunlar |
endi boyag'i qarag'anda biroz yengillangansumon jon olg'uchi qora ko'zlari harakatlana boshlag'an, bo'g'riqqan qizil yuzlari ochilinqirag'an edilar. | endi boyog'i qarag'anda biroz yengillangan simon jon olg'uchi qora ko'zlari harakatlana boshlagan bo'bo'g'ruqqan qizil yuzlari ochilimqiragan etilari | endi boyog'i qaraganda biroz yengillangan sumon jon olg'uvchi qora ko'zlari harakatlana boshlag'an bog'ruqqan qizil yuzlari ochilin qirag'an edilar |
|
Women and man interview. High quality audio
|
mana shu boylarni birlashtirib turadigan va deyarli hammasiga xos bo'lgan qanaqa kamchiligi bor u, ko'rsatmaysiz. qanaqa kamchiligi? hammani o'zini kamchiligi bor. bir biriga o'xshash emas. yo'q, o'xshamaydi. yoki o'xshashmiz. yo'q, o'xshaydi deyolmayman kimdir. | mana shu boylarni birlashtirib turadigan va deyarli hammasiga xos bo'lgan qanaqa kamchiligi boru ko'rsatmaysiz qanaqa kamchilig hammani o'zini kamchiligi bor birbiriga o'xshash emas yo'q o'xshab oa yoki o'xshashmi yo'q o'o'xishaydi davomiymankan | mana shu boylani birlashtirib turadigan va deyarli hammasiga xos bo'lgan qanaqa kamchiligi bor u ko'rsatmaysiz qanaqa kamchiligi hammani o'zini kamchiligi bor bir biriga o'xshash emas yo xshyoki o'xshashmi o'qish edi daomiyman |
|
Old audio with bad quality.
Shum Bola |
yarim kechada sheriklaring bilan kelgansan, boy otam sheriklaring bilan tunagansan, pulni qayerga yashirganini sen bilasan. sen, sen, sen! ha, bo'pti! boy otamni ham so'ydim, xokirni ham o'ldirdim, eshakni ham so'ydim, imomni ham o'ldirdim! | yarim kechada sheriklaring bilan kelgansan voya otami sheriklaring bilan tunagansan pulni qayerga yashirganni sen bilasan sen san sanaijamodi damaaaan jamodara 😵💫 | yarim kechada sheriklaring bilan kelgansan boy otamni sheriklaring bilan tunagansan pulni qayerga yashirgandi sen bilasan sansansan aaodam oiao eaodaa 😵💫 |
Thoughts
Let's be honest - most startups don't need open source AI models unless they are facing specific legal restrictions. Gemini 1.5, 2, 2.5 Pro delivers remarkably human-like performance, especially for transcription where it captures nuanced speech with accuracy that rivals human ears. When you hear someone speaking, this model understands exactly as you would.
Commercial solutions like Gemini are production-ready and surprisingly affordable for most business applications. The transcription quality is so refined that it processes audio similar to how human listeners perceive conversations - catching subtle inflections and handling background noise gracefully.
However, when handling sensitive personal data that cannot be shared with foreign third parties, such as private audio recordings containing confidential information, regionally-hosted services or self-hosted open source alternatives (like those based in Uzbekistan) provide necessary compliance without compromising too much on quality.
Implementation Example
Integrating NavaiSTT into your application is straightforward. Here's a Python code example:
import torch
import torchaudio
import numpy as np
from transformers import WhisperProcessor, WhisperForConditionalGeneration
def transcribe_audio(audio_path, model_path):
"""Simple function to transcribe audio with a fine-tuned Whisper model"""
# Load model and processor
processor = WhisperProcessor.from_pretrained(model_path)
model = WhisperForConditionalGeneration.from_pretrained(model_path)
# Move to GPU if available
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
# Load and preprocess audio
waveform, sample_rate = torchaudio.load(audio_path)
if sample_rate != 16000:
waveform = torchaudio.functional.resample(waveform, sample_rate, 16000)
# Convert to mono if needed
if waveform.shape[0] > 1:
waveform = waveform.mean(dim=0, keepdim=True)
# Process audio
input_features = processor(
waveform.squeeze().numpy(),
sampling_rate=16000,
return_tensors="pt"
).input_features.to(device)
# Generate transcription
with torch.no_grad():
predicted_ids = model.generate(input_features)
# Decode
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
return transcription
# Example usage
if __name__ == "__main__":
MODEL_PATH = "islomov/navaistt_v1_medium"
audio_file = "some_audio.wav"
text = transcribe_audio(audio_file, MODEL_PATH)
print(f"Transcription: {text}")Support Open Source
If you find this work valuable, please consider supporting my efforts to create more open-source tools for the Uzbek language. Your contribution helps cover costs and fuels future development.